

Learn about Convolutional Neural Network CNNs and their layers, their benefits, limitations and applications in real life in a simple and straightforward manner.

Convolutional Neural Networks (CNNs).
Introduction
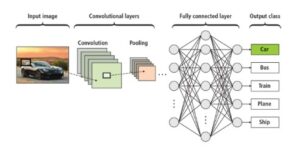
Convolutional Neural Networks (commonly written as CNNs) are a type of deep learning framework that is especially suited to analyze structured information such as images, videos, and signals. They are motivated by the biology of the visual cortex in animals, where groups of neurons are specifically sensitive to particular visual patterns: edges, colors, and textures. The CNNs have been hailed as pillars in the application of computer vision including image recognition, object detection, face recognition and even natural language processing tasks.
The CNNs are architecturally different, unlike in a typical feedforward neural network where all neurons are interconnected with all other neurons in the subsequent layer. They take advantage of data spatial hierarchies, i.e., they are processed locally and constructed in layers. This design is an order of magnitude leaner with respect to parameters, produces higher computational performance and scalability, and enables CNNs to fit real-world tasks.


Key Components of CNNs
- Convolutional Layer
The basic unit of CNNs is the convolutional layer. It works with a mathematical operation known as convolution of the input. This layer does not connect all the neurons with the entire input, but with filters (kernels) sliding across small sections of the input data.
- The filters are small matrices (e.g. 3 x 3 or 5 x 5).
- The filter scans through the input image and performs element-wise multiplication and summations to form a feature map.
- Different features (edges, textures, corners, etc.) can be detected with different filters.
To take an example, in an image one filter can be taught gradient lines (vertical edges) whereas another can be taught diagonal patterns. CNNs are trained to automatically learn the most optimal filters to the task at hand.

- Activation Function
CNNs use an activation function after the convolution operation, the most popular of which is the Rectified Linear Unit (ReLU). ReLU is used to transform negative values to zero and preserve positive values.
- This adds non-linearity to the model and allows CNNs to learn complicated patterns.
- CNNs with no activation functions would act like only a simple linear system, which is highly restrictive.
- Pooling Layer
The pooling layer minimizes the spatial scale of feature maps which is useful because:
- Reduce the size of parameters.
- Reduce computational cost.
- Resistant to the variations like rotation or translation in the input to make the network stronger.
Max pooling is the most popular pooling algorithm, in which the maximum value of each patch of the feature map is picked. In the example, a 2×2 max pooling would halve the size of a feature map in both dimensions.
- Fully Connected Layer
Following a few convolutional and pooling layers, the final result is flattened to a single-dimensional output and sent through one or more fully connected layers. These layers operate similarly to the regular neural networks, and all the extracted features are combined to make predictions.
To perform classification, it is typically the last fully connected layer that employs the softmax function, which transforms the results into the probability of each possible classification.
- Dropout and Regularization
CNNs may tend to overfit when trained on small sets. In order to solve this, methods like dropout are employed. Training Dropout simply disables a per cent of the neurons randomly; this prevents the network from using a particular path too often, and induces improved generalisation. This is also because of weight regularization (L1/L2 penalties).
Training a CNN
The process of training a CNN can be thought of as modifying the filters and weights using a process known as backpropagation with an optimizing algorithm such as stochastic gradient descent (SGD) or Adam.
Steps in training:
- Forward Pass: It is an algorithm used to predict by going through convolutional, pooling, and fully connected layers using the input image.
- Loss Function: Loss function is a per-label prediction error (ex: cross-entropy loss).
- Backward Pass: The values of the loss with respect to filters and weights are then calculated through backpropagation.
- Weight Update: The optimizer is used to update weights and filters in order to reduce loss.
With this process, many epochs are carried out until the model gives good performance.
Advantages of CNNs
- Automatic Feature Extraction: CNNs unlike traditional machine learning can extract features automatically.
- Efficiency of the parameters: CNNs are much more efficient in terms of the number of parameters used compared to fully connected networks since they have local connections and share weights.
- Translation Invariance: CNNs are resistant to changes and movements in the input through convolution and pooling.
- Scalability: CNNs also scale well with high-dimensional and large tasks like high-resolution images and video.
Applications of CNNs
CNNs have transformed many areas, especially in computer vision but not exclusively.
- Image Classification
CNNs drive state-of-art models on tasks such as classifying pictures into categories (e.g. classifying dogs vs. cats). The models like AlexNet (2012), VGGNet (2014), or ResNet (2015) proved their tremendous power.
- Object Recognition and Detection.
R-CNN, YOLO (You Only Look Once), and SSD (Single Shot MultiBox Detector) CNN-based networks can identify and classify various objects in an image in real-time, which is essential in autonomous driving, surveillance, and robotics.
- Facial Recognition
FaceNet and other systems like it train CNNs to learn face embeddings, which can be used in security systems and personal devices to provide the highest accuracy during face recognition.
- Medical Imaging
CNNs help physicians to diagnose diseases through X-rays, MRIs and CT scans. They are very effective in identifying tumors, fractures and other abnormalities.
- Nature of Language Processing (NLP)?
Despite the prevalence of recurrent networks and transformers in NLP, CNNs have been applied in text classification, sentiment analysis and language modeling as 1-D sequence processors.
- Autonomous Vehicles
CNNs are used to interpret video data, in real time, by cameras to assist cars in identifying pedestrians, road signs, and road hazards.
Challenges and Limitations
- Data Hunger: CNNs need big labeled datasets to work well. Lack of sufficient data can make them overfit.
- Computational Cost: CNNs are computationally expensive and usually require either GPUs or TPUs to train.
- Interpretability: CNNs have been labeled as black boxes because it is hard to tell why the models make certain predictions.
- Resistance to Adversarial Attacks: CNNs are susceptible to small, carefully constructed perturbations of input data that can cause them to provide incorrect predictions.


New future versions and enhancements.
To solve CNN issues, many architectures have been developed by researchers:
- ResNet (Residual Networks): Skips connections are used to train extremely deep networks with disappearing gradients.
- DenseNet: Each layer is connected to all the other layers to enhance the use of features.
- MobileNet and EfficientNet: Mobile and embedded network CNNs.
- Capsule Networks: These have been proposed with an aim of better modeling spatial relationships as compared to the classic CNNs.
Furthermore, CNNs are commonly used with other architectures as hybrid models in vision and multimodal tasks.
Future of CNNs
Although more modern models, such as Vision Transformers (ViTs) are becoming more popular, CNNs are still very relevant. They are also competitive in tasks with limited information, less training time is required than transformers and are also fundamental in a host of applications in real time. Additionally, their use is being reinforced by research into their interpretability, efficiency, and robustness.
Conclusion
Convolutional Neural Networks has revolutionized the field of artificial intelligence, especially in computer vision. They can easily learn hierarchical patterns of raw data due to their peculiar structure which is based on the human visual system. CNNs are among the most powerful tools of deep learning despite their high data demands and lack of interpretability. In health care or self-driving cars, CNNs are already pushing the limits of machine vision and understanding, and their development will certainly influence the future of AI.
Also read- AI can read animal mind