
U.S. web and application outages (or downtime) can occur due to a number of different causes: technical, environmental, or human. The following is a breakdown of the most prevalent causes.

Causes of outages
-
Server or Hardware Failures.
- Applications and websites are dependent on servers (computers that store their data and code).
- When a server malfunctions or dies, becomes limited (CPU, RAM, disk space), or the hardware fails, the site or application may be brought down.
- Example Thousands of websites can be impacted simultaneously by AWS or Google Cloud data center failure.
-
Downtime of Data centers or Cloud providers.
- Most American applications deploy large providers such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud.
- When something goes wrong with one of their regions like the failure of cooling, fire, software bug, etc. a lot of big apps will go offline.
- Examples: Netflix, Slack and Reddit have been struck by AWS East region outages in the past.
-
Network or DNS Problems.
- Domain Name System (DNS): The Domain Name System translates name of the website (such as that of Google) into an IP address.
- When the DNS servers go down or are configured improperly, then users will not be able to access the site even when the servers are operating correctly.
- Also, the problems with Internet Service Providers (ISP) or Content delivery networks (CDN) (such as Cloudflare, Akamai) may prevent access on a national scale.
-
Software Updates or Code Bugs.
- During the implementation of new releases, the developer can crash or shut down the system due to a bug or compatibility problem.
- In case of failure of rollback systems or testing environs, users will encounter Service unavailable or 500 error.
-
DDoS attacks or Hacking.
- A DDoS attack overwhelms a webpage with bogus traffic, as well as servers.
- Other security breaches or ransomware attacks may cause temporary shutdowns to protect them or investigate them.
-
Human Error.
- Examples Misconfigurations, mishandled deletions by engineers or incorrectly-pushed code by engineers can cause outages.
- Even the largest tech companies such as Facebook and Google have suffered major downtime due to one configuration error.
-
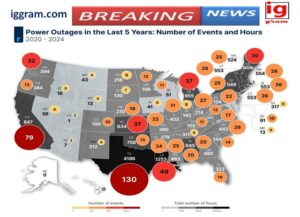
Natural Disasters or Power Failure.
- Storms, earthquakes or regional blackouts can also affect the data centers, particularly when there are failures in backup generators.
-
High Traffic Surges.
- Instead of being scaled, suddenly increasing user traffic (e.g. sale of concert tickets, big news events, Black Friday) can bring servers to a crawl.
Example:
In October 2021, Facebook, Instagram, and WhatsApp also went offline worldwide due to a bad update in configuration that targeted their backbone routers and disconnected them to the internet over 6 hours.
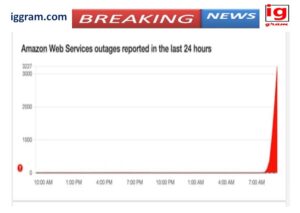
how businesses avoid, reduce, and bounce back swiftly on outages of their websites or apps in the U.S. (and everywhere else).
-
Loss (Backup Systems Everywhere)
Businesses never depend on a single server or data center.
They apply the redundant systems- copies that automatically come into play in case of failure of one of them.
- Example: When one of the data centers in Virginia goes offline, traffic automatically re-routes to a data center in California or Texas.
- This is what is referred to as High Availability (HA).
Tools/Practices: load balancers, multi-regions (Multi-region deployment), backup servers and replicated databases.
-
Load Balancing
A load balancer distributes the incoming traffic evenly among a number of servers.
In the event of failure or overloading of one server, the load balancer redirects traffic to different servers – avoiding a complete failure.
Flattened hierarchy Google Search has thousands of load balancers to make sure that even a billion requests a day won’t ruin it.
-
Scalability (Auto-Scaling) of the Cloud.
Cloud computing is implemented in modern applications to ensure the expansion or reduction of server capacity based on high traffic.
- Cloud providers automatically add computing power when users spike (as is the case with a flash sale).
- Scaling-down of servers when traffic reduces will save money, and will help avoid overloading.
Examples of services: AWS auto scaling, Google cloud compute engine and Azure auto scale.
-
Data Backups & Replication.
To ensure that important data would not be lost in case of outages or cyberattacks:
- There are hourly/Daily automatic backups to other locations.
- Database replication makes sure that there are real time copying of data in different regions.
Should one database go down, an immediate replacement is effected by a second database (so-called failover database).
-
Disaster Recovery (DR) Plans.
All significant technology firms have a Disaster Recovery Plan – the step-by-step manual on what should be done in the event of system failure.
This includes:
- Instantaneous backup server switch-over (failover)
- Restoring data from backups
- Reconnecting internal tools and APIs.
- Notifying users and stakeholders.
Goal: 1000 times the RTO (Recovery Time Objective) -the speed at which services are brought back.

-
Monitoring & Alert Systems.
Constant surveillance eliminates problems before users realize.
Monitoring tools such as Buddy systems such as Datadog, New Relic, or Prometheus monitor:
- Server health
- Traffic spikes
- Error rates
- Latency
In the case of something happening, engineers have automatic notifications (email, Slack, SMS) to act within a few minutes.
-
Staging and Testing, Pre-Deployment.
Prior to their release of new updates:
- Code is coded in a staging (a copy of the actual system).
- Bugs are early noticed by automated tests.
- To small user groups the deployments are made with a step-by-step (so-called canary releases) approach.
This assists in preventing the pushing of broken updates that may crash down the whole system.
-
Protective Controls on attacks.
In order to secure against DDoS or hacking:
- Rate limiters, traffic filters (such as Cloudflare, Akamai, AWS Shield) and firewalls are utilized.
- Intelligent systems are based on AI and identify and intercept suspicious traffic.
-
Power & Internet Backup.
Data centers have:
- Multiple power grids
- Backup generators
- Battery systems (UPS)
- Multiple ISP connections
This makes them operational even in times of great blackouts or fiber cuts.
-
User Communication & Transparency.
Good companies notify users in a timely manner when outages occur through:
- Status pages (such as they are on status.google.com or [downdetector.com])
- Social media updates
- In-app messages
Openness fosters a sense of trust and the engineers correct the problem.
Example in Action:
In case of server overloading in a single location that Netflix notices:
- Auto-scaling also implements the addition of extra servers immediately.
- Load balancer redirects the traffic to the closest stable.
- There are alerts to engineers to investigate.
- Users have a slightest sense of disruption.
conclusion:
The causes of website and app failures in the U.S. include technical failure, bugs in software, software attack, human errors, or natural disasters. But, the current businesses reduce downtime by using redundancy, load balancing, cloud auto-scaling, disaster recovery plans, backups, monitoring and use of security measures. Most of the outages are brief with such systems which makes the user hardly ever notices the disruption.
In summary: although it is a fact that outages are unavoidable, sufficient infrastructure make digital offerings resilient and reliable due to proactive planning.
Also read- Louvre paris: Robbery of priceless jewelry in 7-minute

1 thought on “Simple 8-step why web and application outages?”